Hier packe ich auch einige HTML und CSS Workframes hinein, weil es an manchen Stellen sehr praktisch ist, auch wenn es hier ausschließlich um JavaScript geht.
Javascript
CSS/ HTML
– Material Design Lite
Baukasten um schnell mal ein neutrales Design zusammenzubauen
IDE:
Die entsprechende IDE mit der ich arbeite und nachfolgend eingerückt die dazugehörigen Plugins und Erweiterungen.
Visual Studio Code (VSCode)
Entwicklungsumgebung mit Code-Vervollständigung, guten Support und sehr guten Erweiterungen.
Five Server (Live Server) – Erweiterung
Damit wird ein lokaler Server eingerichtet, der während der Entwicklung mitläuft und alle Änderungen live verfolgt werden können. Damit spart man sich wiederholtes speichern und neu laden im Browser. Wird in VSCode installiert und muss nicht separat heruntergeladen werden. TIPP: Kann man, wenn man am HTML arbeitet auch schon fast als Echtzeit-HTML-Editor bezeichnen.
VS Color Picker
Tool für die Farbauswahl in z.B. HTML Dateien.
Markdown und HTML Sprungmarken bzw. Querverweise innerhalb eines Dokuments
Links innerhalb HTML und Markdown Dokumenten
Kurz in eigenes Sache, ich schreibe so gut wie alle meine Texte in reinen Markdown. Wandel diese bei Bedarf selbst in HTML um oder verarbeite es mit zB. Pandoc weiter. Bei langen Artikeln oder einem E-Book stellt man sich dann die Frage, wie erstelle ich eine Sprungmarke innerhalb des Dokuments. Sagen wir mal vom Inhaltsverzeichnis zur richtigen Stelle? Inhaltsverzeichnis mit Markdown erstellen ist sowieso so eine Sache.
Eins vorweg, Markdown stellt dazu nur indirekt ein Werkzeug zur Verfügung. Allerdings lässt sich HTML und Markdown sehr gut mischen, daher machen wir einen kleinen Umweg.
Zuerst erstellen wir einen Link und verweisen auf einen Anker in Markdown:
[Kapitel 1](#kapitel1)
Der Teil in den eckigen Klammern ist das, was man später sehen kann, in den runden Klammern befindet sich der Name des Ankers zu dem gesprungen werden soll. Das ganze sieht dann wie folgt aus:
Nun erstellen wir die Stelle an die gesprungen werden soll:
<a id="kapitel1"></a>
## Kapitel 1
oder:
<a name="kapitel1"></a>
## Kapitel 1
Dies sieht dann im Browser wie folgt aus:
Kapitel 1
Mit Klick auf den Link Kapitel 1 oben, springt man sofort zur Marke des <a> Tags. Ich persönlich bevorzuge die Sprungmarke immer ein kleines Stück über die eigentliche Stelle zu platzieren, da die meisten Browser fast schon zu weit springen.
Auch nehme ich am liebsten den Namen des <a> Tags als Sprungmarke, theoretisch wäre auch jede beliebige ID eines anderen Tags möglich wie z. B. <div id="kapitel1">. Da ich mich jetzt aber auf Markdown beziehe bleiben wir beim Ersten. Des Weiteren könnte man auch in Namenskonflikte mit Javascript geraten. Sollte aus dem Markdown-Code eh nur PDF Dateien generiert werden, spielt dies eh keine Rolle.
Änderungslog:
2024-04-22 09:32:55 Monday <a name= gegen <a id= getauscht/ ergänzt
Der Avorion Distanzrechner ist ein einfacher Rechner der für Computerspiel Avorion verwendet wird um in einem Feld die Entfernung von der eigenen Position zur Mittelpunkt-Koordinate (0:0) berechnet.
Die Karte besteht aus 1000 * 1000 Feldern und ist in die Koordinaten -500:500 (oben links) bis 500:-500 (unten rechts eingeteilt). Den Mittelpunkt stellt die Koordinate 0:0 dar. Hier ist der Auschnitt eines Screenshots Avorion Karte der Karte aus dem Spiel zu sehen.
Problemdarstellung und Lösung:
im Ersten Schritt möchte ich das der Anwender einfach nur seine Koordinaten im Format X:Y eingibt und den Abstand zu 0:0 als Ergebniss erhällt. Dazu lautet die Formel: distanz = wurzel aus (x^2 + y^2)
im Zweiten Schritt soll der Anwender auch das Ziel selbst wählen können. Standartmässig bleibt es aber auf 0:0 stehen.
Entwicklung:
Programmiersprache: C#
Da das kleine Projekt im Rahmen der Lernphase zu C# entstanden ist und mein erstes kleines Ziel darstellte, habe ich selbsterklärend die Programmiersprache C-Sharp gewählt.
In C# würde die Berechnung des ersten Schrittes wie folgt aussehen:
11.01.2022
Da ich als Neuling mit dem VisualStudio 2022 auf nicht vorhersehbare Probleme gestossen bin, stelle ich C# erst einmal zurück. Vieleicht war C# doch keine so gute Idee. Es gibt Probleme mit dem Paketieren der Software, ausserdem benötige ich wohl eine weitere Windows 10 Lizenz für die Virtuelle Maschine zum testen.
Programmiersprache: JavaScript
Die aktuelle Version des Avorion-Distanzrechners ist HIER zu finden.
Dieser Beitrag fasst den täglichen Umgang mit GIT zusammen. Er zeigt ohne Umwege anhand eines Beispielprojektes den allgemeinen Umgang mit GIT. Wenn man das erste mal mit GIT zutun bekommt, kann der Funktionsumfang einen überwältigen. In der Praxis braucht man aber als Entwickler relativ wenig davon. Wenn man die Grundprinzipien von GIT verstanden hat kann man mit der Zeit sein Wissen erweitern.
Ich hatte damals, als ich das erste mal mit GIT zutun bekam, zwar viel Literatur gefunden da GIT extrem gut dokumentiert und gepflegt ist, aber ein richtiges Praxisbeispiel fehlte.
Vorwort
Grundlagen
Ein neues Projekt beginnen
Änderungen ins Repository einpflegen
Versionen Verwalten
Einen HOTFIX erstellen
Ups, es ist etwa schief gegangen
Vorwort
Wozu Versionverwaltung und wieso gerade git?
Grundlagen
Kannst Du gerne woanders nachlesen. Ich habe da etwas rausgesucht, hier [1] , hier [2] und hier [3] hast Du einige Grundlagen. Ganz kurz in wenigen Worten: GIT ist eine Versionsverwaltung um Softwarecode, Dokumente oder was auch immer zu verwalten und im Team zu koordinieren. Letztendlich ist Git ein Werkzeug für die Versionsverwaltung, es macht wie es heißt: Versionen-Verwalten
Ein neues Projekt beginnen
Repository erstellen
Zu beginn eines Projekts sollte man ganz normal anfangen zu programmieren, ab irgend einem Zeitpunkt, am besten so früh wie möglich sollte man dann ein Repository erstellen. Hat man ein bereits bestehendes Projekt, kann man selbstverständlich ein Repository erstellen und das vorhandene Projekt hineinkopieren.
Noch einfacher ist es indem man einfach in das Hauptverzeichnis des Projekts wechelt und ein einfaches
git init
anwendet. Schon steht das ganze Projekt „theoretisch“ unter Versionsverwaltung. Noch wurde allerdings keine Momentaufnahme der Dateien vorgenommen, dies geschieht mit dem ersten commit, dazu gleich mehr.
GIT bare Repository
git init --bare
Ein sogenanntes bare-Repository ist ein Repository ohne Arbeitsbereich oder sogenannten Work-Flow. Wenn man ein normales git init ausführt wird ein Repository initialisiert wie oben bereits erwähnt. Ein bare-Repository ist ein Repository OHNE die eigentlichen Dateien. Dieses Repository dient einzig und allein dazu Versionen zu verteilen. In der Praxis als Entwickler könnte es so aussehen das man bei Arbeitsbeginn mit einem git clone eine Arbeitskopie auf seinem Rechner erstellt und abends wieder pusht.
Keinesfalls sollte man IN diesem Verzeichnis arbeiten, keine manuellen Änderungen vornehmen und nichts hinein kopieren oder löschen.
Eigentlich wollte ich einen kurzen knappen Beitrag darüber schreiben, wie man Software am besten versioniert. Nach kurzer Überlegung fiel mir aber sehr schnell SemVer ein, ein Verfahren, das sich eigentlich perfekt durchgesetzt hat, aber noch nicht einmal im deutschsprachigen Wikipedia-Artikel Einklang findet außer einen Link.
Dokumentenstatus: – in Entwicklung – Stand: 13/01/2019
Als erstes mal den Wikipedia-Artikel lesen. Kurz gesagt ist Markdown eine Aufzeichnungssprache wie z.B HTML mit einem gewaltigen Vorteil: Markdown kann man auch ohne irgend einem Anzeigeprogramm mit einem ganz üblichen Editor wie vim, nano oder Notepad lesen. Dieses Format lässt sich nahezu in jedes beliebige Format übersetzen. Ich erstelle und Compiliere Markdown Dateien mit folgenden
Programmpaketen:
Editor: vim und texmaker sowie LyX
Parser: pandoc
Der allergrößte Vorteil von Markdown besteht tatsächlich darin das man es auch problemlos im reinen Textformat leicht lesen kann ohne irgend welche zusätzlichen Programme.
bei ncurses bin ich einmal auf ein Problem gestoßen das mvprintw() einen Pointer auf char-Array (int printw(const char *fmt, …) erwartet. Ich hatte aber nur Zahlen die dargestellt werden sollten. Es musste also eine Funktion her die den int in einen String, Char oder Array umwandelt. Ein itoa() ist ja nicht immer verfügbar. Hier meine eigene Implementation, das sie nicht unbedingt die schnellste ist leuchtet ein aber es geht mir hier eher um die Vorgehensweise:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
#include <stdlib.h>
#define ASCII_SHIFT 48
/**
* Wandelt einen int in *char um
*
* @param i als Integer
* @return unsigned *char
*/
unsignedchar *int2str(int i){
unsignedchar *str;
int len, tmp, c;
/* Platz schaffen fuer negatives Vorzeichen falls i negativ ist */
len = (i < 0) ? 2 : 1;
/* berechnen wieviele Zeichen benötigt werden */
for(tmp = i; tmp != 0; tmp /= 10){
len++;
}
/* Unbedingt an der Stelle an der aufgerufen wird den Speicher wieder
* freigeben! */
str = malloc(sizeof(char) * len);
/* Den gesamten String füllen
* Ohne Fuellen habe ich am ende des Strings immer undefinierte Zeichen */
for(tmp = 0; tmp <= len; tmp++){
str[tmp] = '\0';
}
/* Ein Zeichen zurueckspringen, letztes Zeichen ist bereits
* 0-terminiert */
len--;
/* Übergebene Zahl ist negativ?*/
if(i < 0){
str[0] = '-';
}
/* Ist die übergebene Zahl etwa eine 0?
* Wenn ja nur eine 0 einfuegen an erster Stelle.
*/
if(i == 0){
str[0] = '0';
}else{
/* Die Zahlen in Zeichen umwandeln */
for(tmp = i, len--; tmp != 0;){
c = (tmp >= 0) ? (tmp % 10) : (tmp % 10) * -1;
str[len--] = (char)(c + ASCII_SHIFT);
tmp /= 10;
}
}
return str;
}
#include <stdlib.h>
#define ASCII_SHIFT 48
/**
* Wandelt einen int in *char um
*
* @param i als Integer
* @return unsigned *char
*/
unsigned char *int2str(int i) {
unsigned char *str;
int len, tmp, c;
/* Platz schaffen fuer negatives Vorzeichen falls i negativ ist */
len = (i < 0) ? 2 : 1;
/* berechnen wieviele Zeichen benötigt werden */
for (tmp = i; tmp != 0; tmp /= 10) {
len++;
}
/* Unbedingt an der Stelle an der aufgerufen wird den Speicher wieder
* freigeben! */
str = malloc(sizeof (char) * len);
/* Den gesamten String füllen
* Ohne Fuellen habe ich am ende des Strings immer undefinierte Zeichen */
for (tmp = 0; tmp <= len; tmp++) {
str[tmp] = '\0';
}
/* Ein Zeichen zurueckspringen, letztes Zeichen ist bereits
* 0-terminiert */
len--;
/* Übergebene Zahl ist negativ?*/
if (i < 0) {
str[0] = '-';
}
/* Ist die übergebene Zahl etwa eine 0?
* Wenn ja nur eine 0 einfuegen an erster Stelle.
*/
if (i == 0) {
str[0] = '0';
} else {
/* Die Zahlen in Zeichen umwandeln */
for (tmp = i, len--; tmp != 0;) {
c = (tmp >= 0) ? (tmp % 10) : (tmp % 10) * -1;
str[len--] = (char) (c + ASCII_SHIFT);
tmp /= 10;
}
}
return str;
}
#include <stdlib.h>
#define ASCII_SHIFT 48
/**
* Wandelt einen int in *char um
*
* @param i als Integer
* @return unsigned *char
*/
unsigned char *int2str(int i) {
unsigned char *str;
int len, tmp, c;
/* Platz schaffen fuer negatives Vorzeichen falls i negativ ist */
len = (i < 0) ? 2 : 1;
/* berechnen wieviele Zeichen benötigt werden */
for (tmp = i; tmp != 0; tmp /= 10) {
len++;
}
/* Unbedingt an der Stelle an der aufgerufen wird den Speicher wieder
* freigeben! */
str = malloc(sizeof (char) * len);
/* Den gesamten String füllen
* Ohne Fuellen habe ich am ende des Strings immer undefinierte Zeichen */
for (tmp = 0; tmp <= len; tmp++) {
str[tmp] = '\0';
}
/* Ein Zeichen zurueckspringen, letztes Zeichen ist bereits
* 0-terminiert */
len--;
/* Übergebene Zahl ist negativ?*/
if (i < 0) {
str[0] = '-';
}
/* Ist die übergebene Zahl etwa eine 0?
* Wenn ja nur eine 0 einfuegen an erster Stelle.
*/
if (i == 0) {
str[0] = '0';
} else {
/* Die Zahlen in Zeichen umwandeln */
for (tmp = i, len--; tmp != 0;) {
c = (tmp >= 0) ? (tmp % 10) : (tmp % 10) * -1;
str[len--] = (char) (c + ASCII_SHIFT);
tmp /= 10;
}
}
return str;
}
Wichtig ist hier das man den Speicherplatz mit free() wieder freigibt der mit malloc reserviert wurde! Wenn jemand Verbesserungsvorschläge hat dann bitte her damit.
Alternativ kann man das ganze natürlich auch mit sprintf() machen.
Stand: 29/04/2018
letzte Änderung: 2022-01-14 08:25:47 Friday
Code:Blocks auf deutsche Sprache umstellen? Ganz kurz in eigener Sache: eigentlich sollte man als Programmierer nicht unbedingt eine IDE in seine Landessprache stellen und in Englisch arbeiten. Ich habe es manchmal aber dennoch ganz gerne und so stieß ich irgendwie auf dieses kleine aber kniffelige Problem.
Die Originalwiki zu Codeblocks [1] lässt sich da nicht so ganz eindeutig aus und bezieht sich da irgendwie auf Windows etc. Die Anleitung dort lässt sich zumindest nicht eindeutig auf Debian umsetzen.
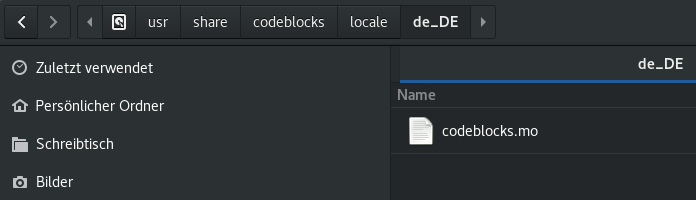
Zuerst muss man sich die bereits übersetze .mo Datei besorgen. Ich habe die gesuchte .mo Datei auf dem FTP-Server geladen [2] und das Original findet man hier [3]. Je nachdem wann Du das hier ließt, wäre es sicherlich besser, wenn Du Dir eine neuere Version besorgst.
Anschließend wird diese Datei nach /usr/share/codeblocks/locale/de_DE kopiert. Sollten die letzten beiden Verzeichnisse nicht vorhanden sein, müssen diese natürlich erstellt werden. Dieser Pfad ist bei mir unter Debian 9 so, Codeblocks wurde über atp installiert.
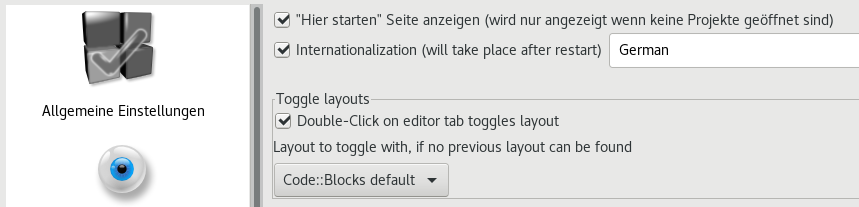
Zum Schluss muss Codeblocks gestartet werden und unter Settings -> Environment -> View finden sich im oberen Bereich Kontrollkästchen, die anzuwählen sind. In Anschluss nur noch die Sprache auswählen und Codeblocks neu starten.
Unter anderen Betriebssystemen kann es durchaus sein, dass die Schritte ein wenig abweichen, vor allem was Pfade angeht. Insgesamt sollte es aber sinngemäß überall gleich sein. Solltest Du Probleme haben, kannst Du mich auch direkt kontaktieren.
Dieser Artikel basiert in der ersten Version auf eigenen Gedanken und dieser Quelle[1]. Oft ist es notwendig bestimmte Angaben eines Programms dauerhaft zu speichern. Diese Angaben stellen die grundlegendsten Einstellungen dar wie z.B welche Datenbank soll beim Programmstart verwendet werden. Alle weiteren Einstellungen könnte man aus der Datenbank laden doch hier geht es um die absoluten Basisdaten.
Grundsätzlich ist es ja bei den ersten Gedanken überhaupt kein Problem solche Angaben zu speichern, da gibt es viele Möglichkeiten. Zum einen einfach in eine Testdatei schreiben oder die alte Properties aus java.util.Properties[2]. Problematisch wird das ganze erst wenn wir uns Plattform-übergreifend bewegen. Hier beschäftigen wir uns aber erst einmal rein mit der java.util.prefs.Preferences[3] Klasse.
Die Preferences Klasse geht bei dem ganzen noch einen Schritt weiter, wir müssen uns als Entwickler gar nicht mehr darum kümmern wo diese Daten gespeichert werden, das erledigt für uns das jeweilige Betriebssystem. Unter Linux liegt es im ~/.java/ Verzeichnis und unter Windows je nach Version im Dokumenten-Ordner, Appdata oder auch der Registry. Dazu später mehr.
Von der o.g Quelle hole ich mal den dort vorliegenden Quelltext, übersetze die Kommentare und arbeite das ganze etwas auf. Zum Schluss gibt es das ganze fertig zum Download und zum ausprobieren. Jetzt eber erst einmal den original Quelltext:
import java.util.prefs.Preferences;
public class PreferenceTest {
private Preferences prefs;
public void setPreference()
{
prefs = Preferences.userRoot().node("/data");
String ID1 = "Test1";
String ID2 = "Test2";
String ID3 = "Test3";
System.out.println(prefs.getBoolean(ID1, true));
System.out.println(prefs.get(ID2, "Hello World"));
System.out.println(prefs.getInt(ID3, 50));
prefs.putBoolean(ID1, false);
prefs.put(ID2, "Hello Europa");
prefs.putInt(ID3, 45);
prefs.remove(ID1);
}
public static void main(String[] args)
{
PreferenceTest test = new PreferenceTest();
test.setPreference();
}
}
import java.util.prefs.Preferences;
public class PreferenceTest {
private Preferences prefs;
public void setPreference()
{
prefs = Preferences.userRoot().node("/data");
String ID1 = "Test1";
String ID2 = "Test2";
String ID3 = "Test3";
System.out.println(prefs.getBoolean(ID1, true));
System.out.println(prefs.get(ID2, "Hello World"));
System.out.println(prefs.getInt(ID3, 50));
prefs.putBoolean(ID1, false);
prefs.put(ID2, "Hello Europa");
prefs.putInt(ID3, 45);
prefs.remove(ID1);
}
public static void main(String[] args)
{
PreferenceTest test = new PreferenceTest();
test.setPreference();
}
}
Was passiert hier nun also?
Ich habe bewusst die Kommentare aus dem Code herausgelassen und hole es hier nun nach. Also:
Zeile 10:
Definieren wir einen „node“, wo die Daten gespeichert werden können. Es gibt da mehrere Möglichkeiten. Hier einfach nur als String in Form eines Pfades. Schau Dir die Klasse im javadoc [3] genauer an, es gibt noch andere Möglichkeiten die nodes zu definieren.
Der überwiegende Teil bezieht sich auf die Nutzerrechte. Globale und lokale Konfiguration als Stichwort.
Zeile 15-17:
Wir laden Werte testweise aus einer eventuell vorhandenen Konfiguration mit der Methode .get diese läd die Daten in eine Variable. Hinter dem Kommata können default-Werte eingetragen werden falls es die Daten oder den ganzen node nicht gibt.
Zeile 19-21:
Hier speichern wir die aktuellen Werte aus den Variablen in unsere Konfiguration.
Zeile 23:
Hier löschen wir testweise einen Wert aus dem node.
Wo werden die Daten gespeichert?
Genau das ist nun der Trick an der ganzen Sache. Wir müssen uns eben nicht darum kümmern WO diese Daten gespeichert werden. Überlassen wir das dem Betriebssystem wo der Container ausgeführt wird. Wie dies allerdings unter Windows und Ubuntu aussieht zeige ich eben an zwei Screenshots.
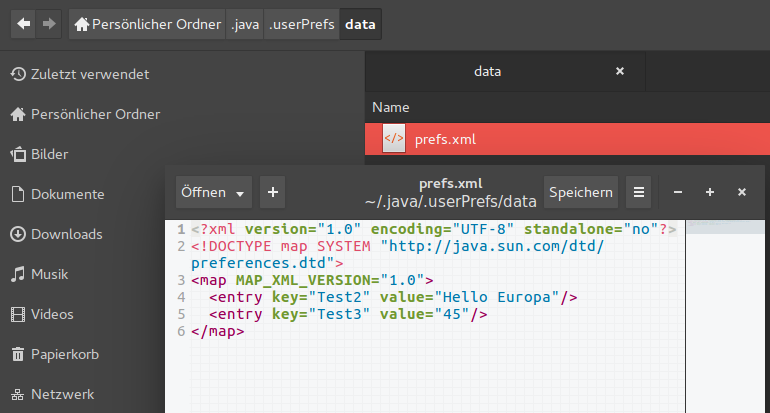
Bild 1 – Linux
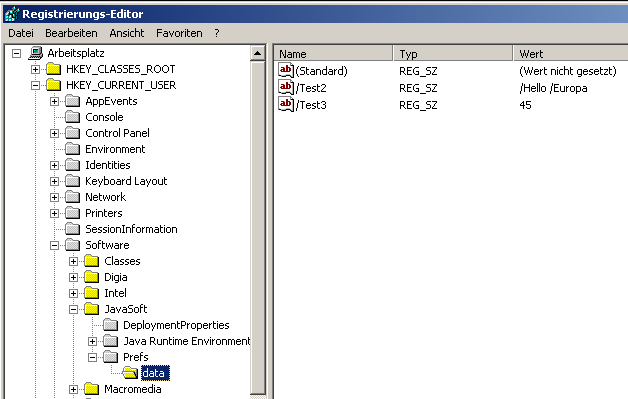
Bild 2 – WindowsXP
Ja genau, ein und der gleiche Code aber unter Linux wird dies unter ~/home/.java/.userPrefs/data/prefs.xml gespeichert und unter Windows in der Registry im Zweig HKEY_CURRENT_USER -> Software -> JavaSoft -> Prefs -> data
Wo dies genau gespeichert wird legen in Zeile 9 fest. Es lässt sich auch definieren das dies im System Zweig der Registry oder /etc/.java unter Linux gespeichert wird. Dazu muss der Container allerdings als Administrator oder root gestartet werden. Ich nehme an es ist verständlich worum es geht.
Eine komplette Liste, wo auf welchem System die nodes gespeichert werden, liefere ich nach aber dies sollte für Dich als Entwickler allerdings zweitrangig sein.
— Fortsetzung folgt …
Achja, ein Tipp am rande. Viele Anfänger tendieren dazu darauf zu bestehen das ihre Daten relativ zum Container gespeichert werden. Am besten in einem Unterverzeichnis unterhalb des Containers. Geht bitte davon ab, das ist nicht wirklich sinnvoll. Stellt euch vor jemand möchte euer Programm an einer globalen Stelle für alle Benutzer installieren. An dieser Stelle hätte der Benutzer der das Programm ausführt gar keine Schreibrechte. Für diesen Einsatz wäre also euer Programm unbrauchbar. Falls es wirklich unbedingt nötig sein sollte, musst Du Dir die Klasse java.util.Properties [2] anschauen die allerdings schon ein paar Jahre auf dem Buckel hat. Dazu gibt es bald noch einen eigenen Beitrag.
Du hast Fragen zur java.util.prefs.Preferences Klasse, Anmerkungen oder bist völlig anderer Meinung? Teile es bitte hier im Forum mit.
Um dir ein optimales Erlebnis zu bieten, verwenden wir Technologien wie Cookies, um Geräteinformationen zu speichern und/oder darauf zuzugreifen. Wenn du diesen Technologien zustimmst, können wir Daten wie das Surfverhalten oder eindeutige IDs auf dieser Website verarbeiten. Wenn du deine Zustimmung nicht erteilst oder zurückziehst, können bestimmte Merkmale und Funktionen beeinträchtigt werden.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.